
เบื้องหลังที่ทำให้ ChatGPT ประสบความสำเร็จคืออะไร?
หลายๆคนก็คงได้ลองใช้ ChatGPT กันแล้วคงรู้ว่ามันสามารถตอบคำถามต่างๆได้ดีมากๆเหมือนคนมาตอบเองเลย
เพราะอะไรมันถึงสามารถตอบคำถามได้ดีแบบนี้ล่ะ นอกจาก parameter ที่มากถึง 175 billion แล้ว ยังเป็นเพราะ RLHF หรือกระบวนการ Reinforcement learning from human feedback ที่ทาง OpenAI ได้เอามาปรับใช้กับ ChatGPT นั่นเอง
ก่อนอื่นเลยเรามาเริ่มกันจากทำความเข้าใจกันก่อนว่า Reinforcement learning คืออะไรกัน
ปกติแล้วกระบวนการที่ AI จะเรียนรู้เนี่ยมีหลายแบบมากเช่น Supervised learning, Unsupervised learning, Reinforcement learning etc.
โดยแต่ละวิธีก็มีข้อดีข้อเสียแตกต่างกันไป ส่วน Reinforcement learning (RL) คือการที่ให้ Agent หรือว่าเจ้า AI ที่เราต้องการให้มันเรียนรู้ เอามันไปอยู่ใน Environment หนึ่งและให้อิสระในการที่จะทำอะไรก็ได้เพื่อให้ได้รับ Reward ที่กำหนดมากที่สุด
ผมขอพูดถึงเวลาคนจะเรียนรู้ก่อนเราจะได้เห็นภาพคล้ายๆกัน สมมุติผมอยากเล่นสกีเป็น ผมก็ต้องเอาตัวเองไปอยู่ในลานสกี (Environment) หัดลงมาจากเขาหลายๆรอบใช่ไหมครับ ลองวางตำแหน่งเท้าหลายๆท่าเพื่อที่จะให้การควบคุมสกีออกมาดี (Action)
ตอนแรกก็ยังเล่นไม่ค่อยได้หรอกล้มไปหลายรอบ (Reward) แต่พอจับหลักได้ก็เล่นได้ดีขึ้นเรื่อยๆถูกไหมครับ
Reinforcement learning เองก็เหมือนกัน เพียงแต่สิ่งที่เกิดขึ้นนี้มันอยู่ใน Simulation บน Computer ล้วนๆ
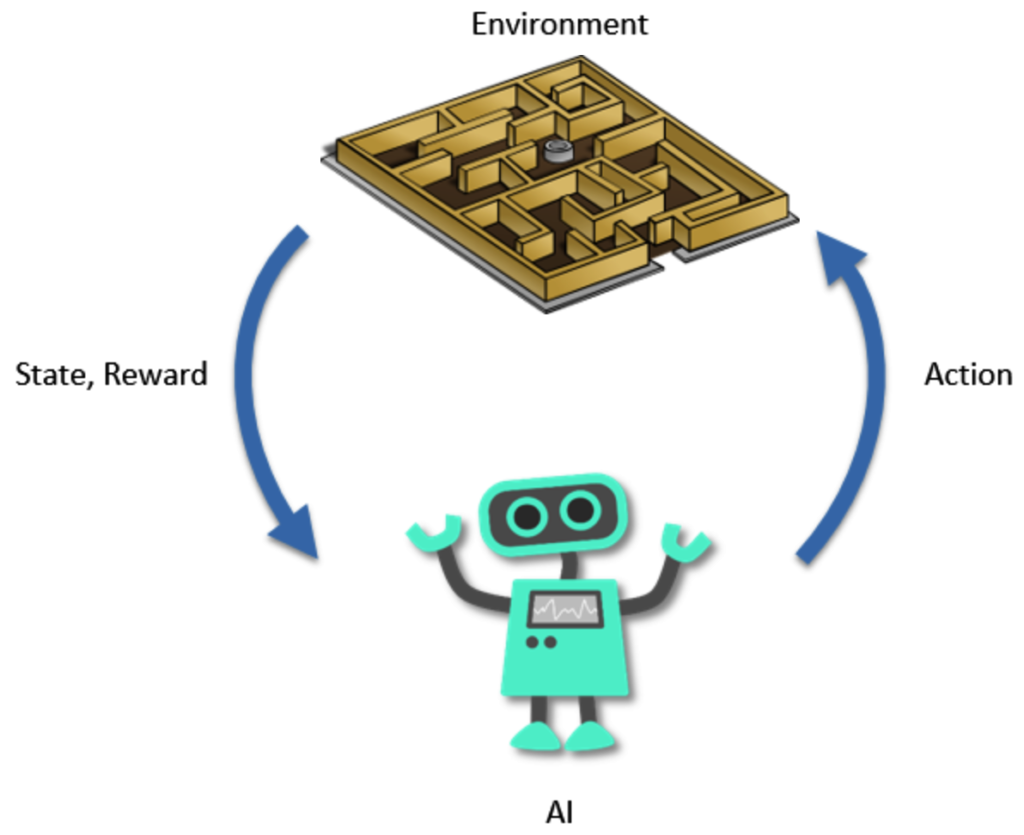
ยกตัวอย่างเช่น Self-driving car
โดยเริ่มแรกเราให้เจ้า AI หรือว่า Agent ไปอยู่ใน Simulation ที่เป็นถนน แล้วจำลองสถานการณ์เพื่อให้ AI ตัดสินใจ
โดย Action ตรงนี้ก็คือ การเบรก ทิศทาง หรือการกดคันเร่งนั่นเอง และถ้ามันขับออกมาดีไม่ช้าไปไม่เร็วไปและไม่ชน
Interpreter หรือว่าผู้สังเกตการณ์ก็จะให้ Reward กับ Agent แล้ว update State เพื่อให้ Agent ไปฝึกในสถานการณ์จำลองใหม่ โดยกระบวนการนี้จะทำซ้ำไปเรื่อยๆ
ถ้าชนได้ Reward 0 หรือไม่ชนได้ Reward 1 เจ้า Agent เองก็จะพยายามควบคุมรถให้ได้ Reward มากที่สุดเป็นต้น ที่นี้เจ้า AI ก็จะขับรถได้ดีขึ้นเรื่อยๆ
ผมขอยกตัวอย่างอีกอันนึงเพิ่อที่จะได้เห็นภาพก็คือให้ AI เล่นซ่อนแอบ
สมุติว่าให้ AI ฝั่งสีแดงเป็นคนหาและสีฟ้าเป็นคนซ่อน
โดย Reward ของสีแดงก็คือการหาสีฟ้าเจอ ส่วน Reward ของสีฟ้าอาจจะเป็นการซ่อนจากสีแดงได้เกินระยะเวลาที่กำหนด
ลองไปดูคลิปนี้จะยิ่งเห็นภาพเลยว่ายิ่งให้ AI ลองผิดลองถูกไปเท่าไหร่ มันก็จะเรียนรู้ในการทำตามเป้าหมายของตัวเองได้ดีขึ้น
Reinforcement Learning From Human feedback (RLHF)
ทีนี้พอเราเข้าใจ Reinforcement learning กันคร่าวๆแล้วก็กลับมาที่ Reinforcement learning from human feedback กันว่าคืออะไร
มันคือการที่ให้ AI เรียนรู้จาก feedback ของคนตามชื่อเลยนั่นเอง
สมมุติว่าเราต้องการจะ train เจ้าตัว ChatGPT ขึ้นมา เราอยากให้ output ของมันออกมาดี เราก็ให้คนมาคอยให้คะแนน output ว่าได้กี่คะแนน เช่นประโยคนี้อ่านไม่รู้เรื่อง เอาไป 1 คะแนน หรือประโยคนี้เขียนดีมากเอาไป 10 คะแนน
จากนั้นก็ให้เจ้า ChatGPT ปรับ output ไปเรื่อยๆเพื่อที่จะให้มันเรียนรู้ในการสร้าง output ออกมาให้ได้คะแนนมากที่สุด
ฟังดูอาจจะง่ายแต่มันใช้เวลาและคนเยอะมากๆ ลองคิดดูว่าถ้าให้คนต้องมาให้คะแนน output ของ ChatGPT เป็นล้านครั้งจะเหนื่อยขนาดไหน หนำซ้ำยังต้องหาผู้เชียวชาญมาให้คะแนนตั้งแต่คำตอบเรื่องทั่วไปยันเขียนโค้ดหรือคิด Business plan etc.
ทีนี้นักวิจัยก็เลยคิดไปคิดมาว่าทำไมเราไม่ให้ AI อีกตัวเป็นคนให้คะแนนแทนซะล่ะ!
OpenAI ก็เลยทำการเทรน AI อีกตัวขึ้นมาเรียกว่า Reward model โดยเจ้า AI นี้จะใช้ text เป็น input แล้ว output เป็นคะแนนออกมา
โดยตอนที่มันเรียนรู้ เราก็จะให้ text คู่ไปกับคะแนนให้เจ้า AI ตัวนี้เรียนรู้จนมันสามารถจับ pattern ได้ว่า text แบบไหนควรจะให้คะแนนเยอะ แบบไหนควรจะให้คะแนนน้อย
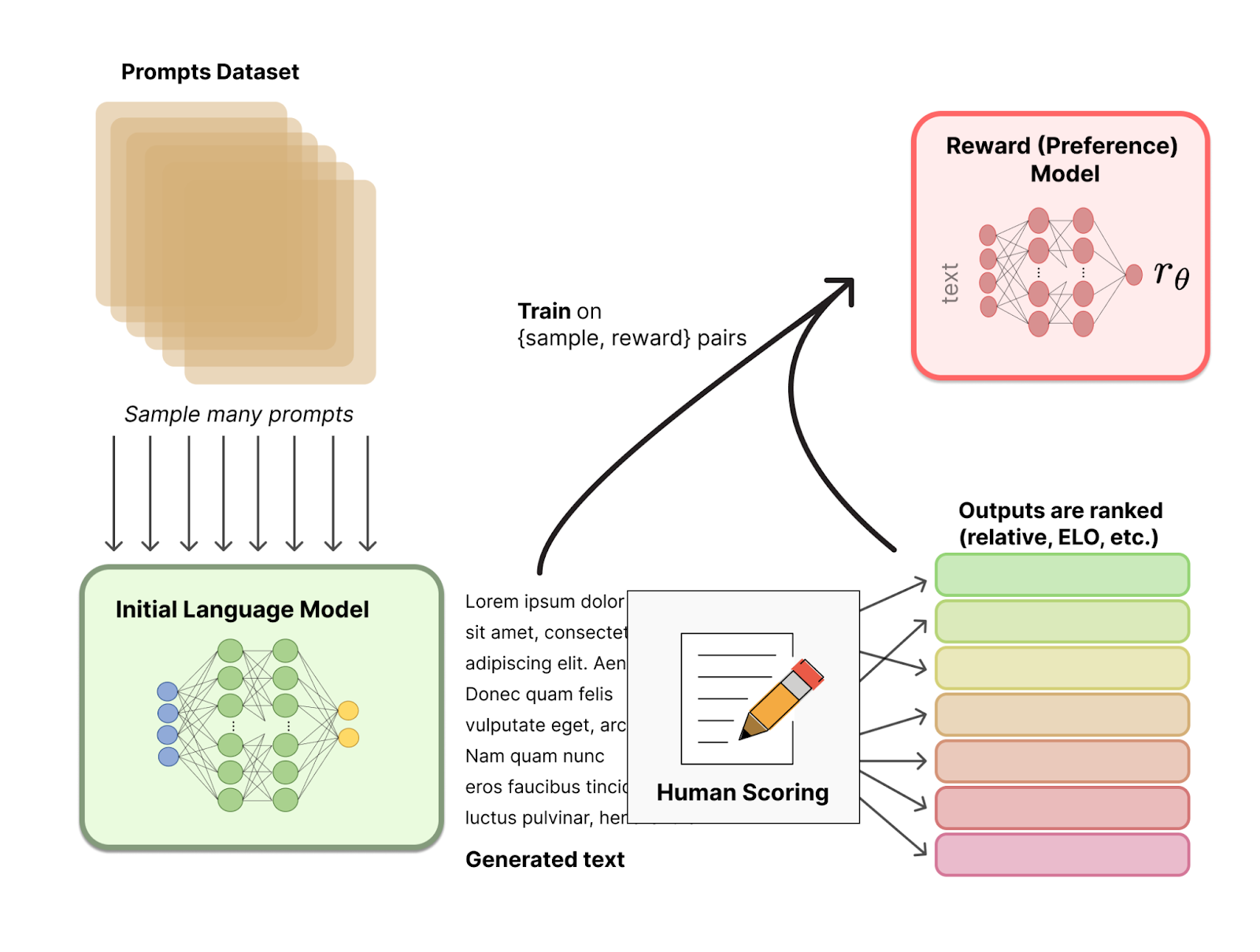
พอได้ Reward model ที่ให้คะแนน text เก่งมากๆแล้ว เราก็นำมันมาให้คะแนน text ที่ ChatGPT สร้าง ทีนี้ก็ไม่ต้องให้คนให้คะแนนเองแล้ว!
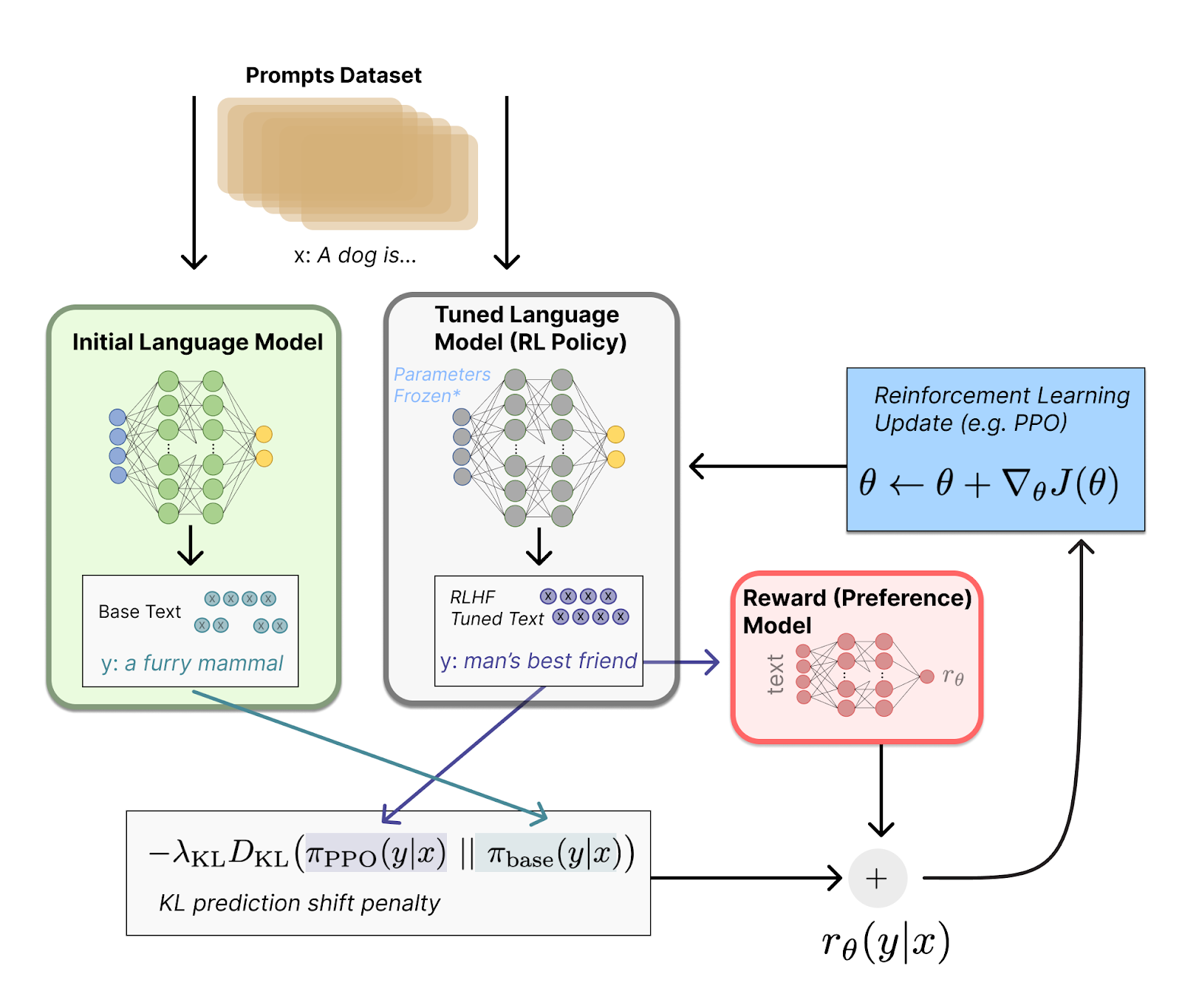
เพิ่มเติมในรูปนี้นิดนึง โดยเจ้า Tuned Language Model คือ ChatGPT ตัวที่เราอยากจะฝึกให้มันเก่งขึ้น ส่วน Initial Language Model เป็นเหมือนกับร่างแรกของมันที่ไม่ได้เก่งมากแต่ยังพอพูดรู้เรื่อง โดยเราเอามาใช้เพื่อที่จะคุม output ของ ChatGPT ไม่ให้ต่างจากตอนเริ่มต้นเกินไป
ไม่งั้น ChatGPT มันอาจจะหาช่องโหว่ของ Reward model จนเจอแล้วพ่นคำมั่วๆออกมาเพื่อให้ได้คะแนนเยอะที่สุดก็ได้
สรุปกระบวนการทั้งหมดคร่าวๆคือเริ่มต้นจาก Prompt ส่งให้ AI text generator ทั้งสองตัวแล้วให้ Reward model โหวตคะแนนของตัวที่เราต้องการเทรน เช็คความแตกต่างของคำตอบทั้งสองตัวจากนั้นก็เอาคะแนนไปอัพเดท parameter ต่างๆเพื่อให้ output ในครั้งหน้าได้คะแนนเยอะขึ้น
จบ! สรุป RLHF ก็คือการสร้าง AI จาก feedback ของคนมาให้คะแนน AI อีกตัวนั่นเอง ด้วยความขี้เกียจของมนุษย์ เราสามารถสร้างอะไรที่ง่ายขึ้นมาใช้ได้เสมอ ไม่ต้องให้คนมาให้คะแนนเองทุกรอบแล้ว สอน AI อีกตัวมาให้คะแนนเองซะเลย
ทุกคนเองก็สามารถเป็นคนที่ให้ feedback ได้เหมือนกันนะอย่างใน ChatGPT หลังจากมันตอบคำถามให้เราแล้วเราก็สามารถเลือกกด Thump up หรือ Thump down ได้ เพื่อที่จะให้ feedback กับ Reward model
ตอนนี้เองหลังจาก ChatGPT ประสบความสำเร็จมากๆที่เอา RLHF มาใช้ก็เริ่มมี AI ทางด้านอื่นเช่น Generative Art อย่าง Stable diffusion ก็นำวิธี RLHF มาปรับใช้เพื่อพัฒนา AI ตัวใหม่ โดยระหว่างนี้กำลังอยู่ในขึ้นตอนเทรนเจ้า Reward model อยู่
โดยเราก็แค่เลือกอันที่คิดว่ามันตรง Prompt มากกว่าเท่านั้นเอง
ใครที่อยากร่วมเป็นส่วนหนึ่งในการพัฒนา AI ก็สามารถไปร่วมสอนเจ้า Reward model ตัวนี้ได้
ถ้ารู้สึกว่าไม่มีรูปไหนเหมือนกว่าจะ Skip เอา หรือใครอยากลองไป Generate รูปฟรีๆก็ทำได้เหมือนกันแลกกับช่วยเลือกว่ารูปไหนดีกว่า
Reference:
https://neptune.ai/blog/reinforcement-learning-applications
https://towardsdatascience.com/applying-of-reinforcement-learning-for-self-driving-cars-8fd87b255b81